进迭时空 Upstream|全球主流大模型开源项目 llama.cpp
作为全球最火的本地大模型推理引擎 llama.cpp,进迭时空(SpacemiT)基于 K3 芯片的 AI 扩展指令集(IME2)成功合入全球主流开源项目 llama.cpp 主线,为端侧大模型推理提供了重要的技术支撑。这意味着进迭时空的AI 软件接口开始全面对外开放,为 RISC-V AI 生态提供了原生、可持续维护的加速基础。
llama.cpp 简介
llama.cpp 是由 ggml-org 维护的开源大模型推理项目,也是当前端侧和本地部署生态中最具影响力的基础设施之一。它以纯 C/C++ 实现为核心,强调少依赖、易部署、跨平台和高性能,已覆盖 CPU、GPU 以及多种异构后端,广泛用于本地推理、边缘设备、轻量化应用和 GGUF 模型生态。
对开发者而言,llama.cpp 不只是一个“跑模型的工具”,更像是端侧大语言模型(LLM)的公共底座。大量模型适配、量化工具、上层应用和设备方案都直接或间接建立在它之上。任何进入 llama.cpp 主干的底层优化,都会迅速辐射到整个产业链。进迭时空正是瞄准这一关键切入点,确保 K3 的 AI 加速能力以官方主线支持的形式进入 llama.cpp。
Upstream 内容
ggml 是 llama.cpp 的计算后端,这次合入的主要内容,是把基于 SpacemiT RISC-V AI 扩展指令的一整套后端优化能力接入到 ggml的 CPU 执行路径中,重点包括以下三个方面:
后端新增 IME2 指令支持
为 SpacemiT 后端新增 IME2 指令(针对 SpacemiT K3)支持
多种量化格式原生支持
支持从 Q2_K、Q3_K、Q4_0 到 Q8_0 等多种量化格式,并通过原生 4bit 矩阵乘指令集实现对 Q4 等量化格式的高效支持
开放 TCM 访问接口及示例
首次开放 TCM(紧耦合内存)访问接口及在大模型上的应用示例
端侧推理的两大核心瓶颈
FFN 访存
吐字阶段,FFN 及其 MoE 变体通常受限于访存,因此业界普遍采用低 bit 量化来压缩权重、降低带宽开销。为兼顾压缩率与精度,主流方案进一步采用 block-wise 量化,即按小块分别缩放,典型如 MXFP8、MXFP4 和 NVFP4。问题在于,ggml 等主流 block-wise 量化格式虽然已将权重量化为 int4、int8 等低比特形式,但许多端侧平台既缺少原生 4bit 指令,也缺少直接匹配 BlockScale 格式的计算能力,导致低比特模型在执行时仍常绕回通用路径,量化收益难以充分落地。
进迭时空 upstream 的这组 patch 基于 SpacemiT A100 支持的vmadot.i4、vmadot.hp.i4等原生4bit指令,将ggml中量化矩阵乘的关键路径正式接入 SpacemiT Matrix/IME 能力范围,解决了这一问题。可以把 vmadot.i4 理解为承担 4bit 点积计算的核心指令;而 vmadot.hp.i4 则是原生 int4 block-wise 量化指令,进一步把点积结果与缩放、累加过程更紧密地衔接起来,减少中间转换和额外搬运带来的损耗。使得 FFN 这类推理过程中最重、最频繁的负载,就有机会稳定落到硬件原生低比特加速路径上。详细指令可参考:
https://github.com/spacemit-com/docs-ai/blob/main/zh/architecture/ime_extension.mdi
长上下文下的 Attention 计算瓶颈
长上下文对话中,每生成一个新 token 都要回看全部历史 KV Cache。随着上下文变长,Attention 涉及的 K/V 数据持续增长,而单步 FFN 规模并不会同步放大,因此在这个场景下,压力会逐步集中到 KV Cache 即 Attention 计算路径。
进迭时空 upstream 的 patch 围绕 1024-bit RVV 以及首次开放的 TCM 访问接口,针对 Attention 计算路径进行了专项优化。在满足对应向量宽度条件时,内核会按照 1024 位 RVV 重新组织 Q、K、V 的分块布局与访存方式,使 QK 计算、softmax 后的权重累加以及 PV 更新都尽可能在宽向量路径上完成,省去权重的重复读入寄存器操作。同时,每个 A100 核独享的 384KB TCM(类比于 GPU Shared Memory)将整个 FlashAttention 计算中的高频反复读写缓存区(如分块后的 Q/K/V 数据、中间的 KQ 分数、掩码以及输出累加区)按固定的区块大小存放,并逐块进行计算,从而降低 KV 相关计算的带宽压力,显著提高长上下文 token 吞吐。
为何本次 upstream 至关重要?
软件接口全面开放
进迭时空面向 AI 计算的软件接口开始更完整地对外开放。无论是 IME 指令能力,还是 TCM 在大模型场景中的使用方式,都不再只是平台内部能力,而是以官方代码和优化示例的形式进入开发者可直接参考、复用的范畴。
可持续维护的基础
随着本次 PR 正式进入 llama.cpp 上游主干,平台对各类大模型推理的支持开始具备官方、原生、可持续维护的基础。开发者直接使用官方仓库和构建流程,即可获得对应的平台加速能力,不再需要长期依赖厂商私有分支。
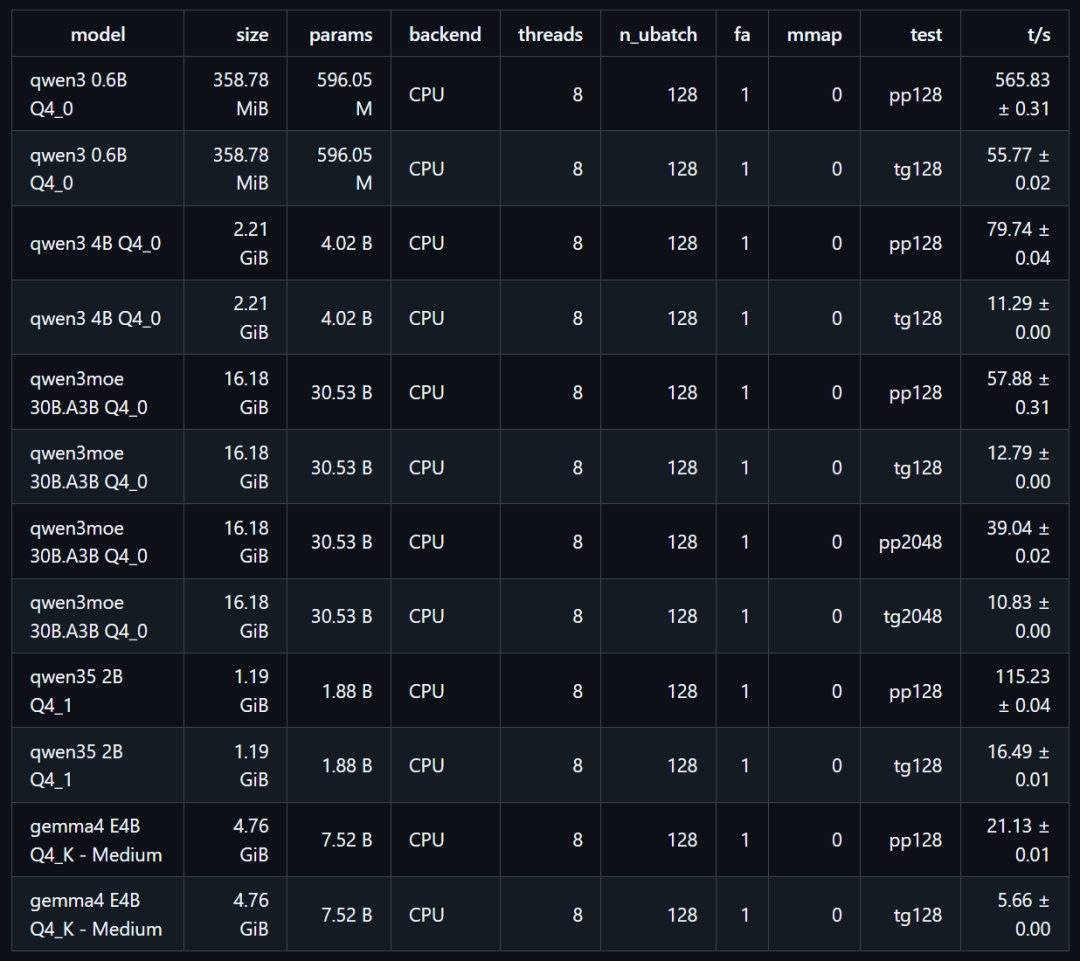
性能实测
以下模型性能均由 Upstream 版本构建,且不在基于大模型推理调整的 Bianbu 内核系统上运行。若采用具备大页内存、Shared TCM 同步优化的内核系统,Qwen3 - 30B - A3B 相同模型的性能可达到 14.5 token/s。
开源聚力前行
未来,进迭时空将持续开放 AI 计算能力,陆续推出包括 K3 指令集详解、A100 编程模型、Triton DSL 分享等系列文章与开源工作,敬请期待。
我们坚信,通过持续的 Upstream 深度开源实践,RISC - V 不仅能提供高性能的硬件算力,也能构建一个比肩现有架构的端侧 AI 软件生态。进迭时空将持续与全球开发者同行,共同推动 AI 计算技术的创新与发展,也期望更多开发者能够一起参与到 RISC-V AI 建设中。
llama.cpp upstream 详情及最新工作进展见:
https://github.com/ggml-org/llama.cpp/pull/22863
进迭时空 Bianbu 系统预装的 llama-server 工具包以 llama.cpp 上游为基础,增加了多模态大模型扩展,也同步进行了开源,相关进展见:
https://github.com/spacemit-com/llama.cpp/tree/spacemit-mtmd
- 艾德克斯分享WAIC 2026世界人工智能大会观察
- 升级!艾感科技推出80L亚克力密封腔体测试系统,320通道并行测试
- 工业串口组网,一台RG3308B32搞定32路串口集中采集
- STM32+WT2003Hx MP3语音芯片UART控制完整工程
- 解锁云知声U2大模型的星辰大海
- 地铁杂散电流监测中ISO系列信号隔离器的应用
- 芯朋微电子推出全平台SiC电机半桥驱动智能功率模块
- 安森美“亮剑”慕尼黑上海电子展,“AIDC”与汽车电子成“重头戏”
- 智能马桶自动开盖雷达感应方案设计
- 鸿道深度参编《中国工业控制产业发展白皮书》,以鸿道操作系统赋能产业智能化升级
- 康谋业务全景速览|自动驾驶仿真、数据闭环、机器人与院校实训一站式方案!
- 香港高校学子赴宁夏开启内地实习之旅
- 变频器的矢量控制技术应用
- 高通全面发布数据中心AI基础设施战略
- RSA5065频谱分析仪的蓝牙信号测试实践
- 探隧者系列 | 51camera隧道综合巡检机器人 守护隧道安全